چرا دیتا مش اهمیت دارد؟
فهرست مطالب
- 1 چرا دیتا مش اهمیت دارد؟
- 2 دیتا مش چیست؟
- 3 چهار اصل کلیدی دیتا مش
- 4 مزایای استفاده از دیتا مش در سازمانها
- 5 چالشها و موانع پیادهسازی دیتا مش
- 6 بهترین رویکردها برای پیادهسازی دیتا مش
- 7 نتیجهگیری: آینده مش دادهها
- 7.1 نقش مش دادهها در تحولات آینده سازمانها
- 7.2 مش دادهها به عنوان ابزاری برای تقویت تصمیمگیری
- 7.3 بسته کامل شرح شغلی برای سازمان ها و شرکت ها
- 7.4 داشبورد مالی و بهای تمام شده – Working Capital in Power BI
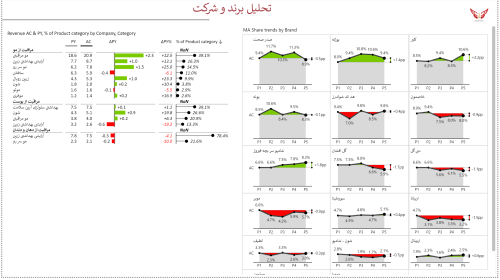
- 7.5 داشبورد کالاهای مصرفی تندگردش – Brand and Product Portfolio Analysis Power BI Template
- 7.6 قالب اکسل داشبورد مدیریت منابع انسانی
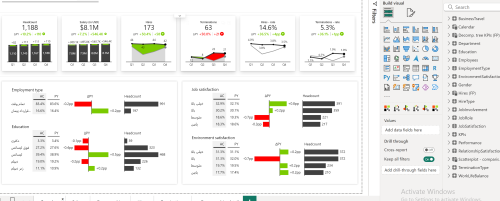
- 7.7 داشبورد منابع انسانی – HR Analytics in Power BI
- 7.8 داشبورد شاخص های کلیدی عملکرد تولید و برنامه ریزی | KPI
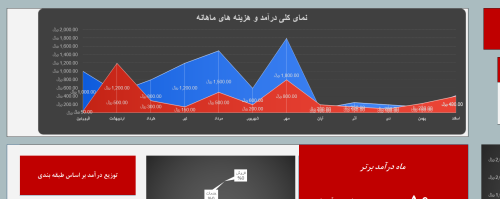
- 7.9 قالب اکسل داشبورد درآمد و هزینه
- 7.10 داشبورد تولید، برنامه ریزی تولید، نگهداری و تعمیرات
- 7.11 داشبورد فروش و بازاریابی – Sales Dashboard in Power BI
- 7.12 قالب اکسل داشبورد مدیریت کارکنان
- 7.13 قالب داشبورد شاخص های مدیریت عملکرد منابع انسانی
- 7.14 داشبورد مدیریت فروش، مشتری، محصول، مالی و حسابداری
- 7.15 بسته کامل فرم ها، شاخص ها و شرح شغل های کسب و کاری
در دنیای دیجیتال امروز، دادهها تبدیل به یک منبع کلیدی برای تصمیمگیری و دستیابی به مزیت رقابتی شدهاند. با این حال، رشد تصاعدی حجم دادهها و افزایش پیچیدگیهای سازمانی باعث شده است که بسیاری از کسبوکارها با چالشهای جدیدی در زمینه مدیریت دادهها مواجه شوند. در مدلهای سنتی مانند انبار داده (Data Warehouse) یا دریاچههای داده (Data Lake)، سازمانها اغلب از ساختارهای متمرکز استفاده میکنند که این ساختارها در مواجهه با افزایش حجم و تنوع دادهها، دچار کاهش کارایی میشوند. این مدلهای متمرکز به تیمهای فناوری اطلاعات (IT) وابسته هستند و باعث ایجاد گلوگاههای مدیریتی و کندی در دسترسی به دادهها میشوند. به همین دلیل، بسیاری از کسبوکارها نمیتوانند به سرعت و دقت مورد نیاز به دادهها دسترسی پیدا کنند و از آنها برای بهینهسازی تصمیمگیری استفاده کنند. در چنین شرایطی، نیاز به یک رویکرد جدید به شدت احساس میشود و اینجاست که دیتا مش (مش دادهها) به عنوان یک راهحل نوآورانه وارد صحنه میشود.
دیتا مش یک رویکرد مدرن برای مدیریت دادهها در سازمانها است که به جای تمرکز بر ذخیره و پردازش دادهها در یک مکان مرکزی، مالکیت دادهها را به تیمهای مختلف سازمان توزیع میکند. این تغییر اساسی در نحوه مدیریت و دسترسی به دادهها به کسبوکارها این امکان را میدهد که به طور چابکتر و مقیاسپذیرتر از دادهها استفاده کنند و به واحدهای عملیاتی مختلف قدرت بیشتری برای تصمیمگیری بدهند.
دیتا مش با تأکید بر مفهوم «داده بهعنوان محصول (Data-as-a-Product)»، تیمها را تشویق میکند تا دادههای خود را به عنوان یک محصول قابل استفاده برای دیگر واحدها و تیمها مدیریت کنند. این روش، علاوه بر ارتقای کیفیت و دسترسیپذیری دادهها، امکان توسعه یکپارچهتر و بهرهوری بیشتر در سازمان را فراهم میکند.
بهطور خلاصه، دیتا مش به سازمانها کمک میکند تا از یک مدل متمرکز به یک مدل توزیعشده و انعطافپذیر حرکت کنند که در آن هر واحد بهصورت مستقل و مسئولانه دادههای خود را مدیریت میکند و در نهایت، سازمان قادر است با سرعت بیشتر و کارایی بالاتر از دادهها برای تصمیمگیریهای استراتژیک استفاده کند.
 اهمیت دارد؟ – مشاوره مدیریت رخ")
دیتا مش چیست؟
دیتا مش (مش دادهها) یک رویکرد جدید برای مدیریت دادهها در سازمانهای بزرگ است که با هدف حل چالشهای معماریهای سنتی مانند Data Lake و Data Warehouse ایجاد شده است. در معماریهای سنتی، معمولاً دادهها در یک مکان متمرکز جمعآوری و مدیریت میشوند، که این ساختارها مشکلاتی مانند کندی دسترسی به دادهها، مقیاسپذیری محدود و تمرکز زیاد بر روی تیمهای IT را به همراه دارند. در نتیجه، بسیاری از کسبوکارها با وجود حجم زیاد دادهها، نمیتوانند به سرعت و دقت مورد نیاز به دادهها دسترسی پیدا کنند و از آنها به طور موثر استفاده کنند.
اما دیتا مش این معضلات را با توزیع مسئولیتها در سراسر سازمان و توانمندسازی تیمهای عملیاتی مختلف حل میکند. در مدل مش دادهها، هر تیم یا واحد در سازمان مالکیت دادههای مربوط به خود را بر عهده دارد و به صورت مستقل این دادهها را مدیریت میکند. این ساختار توزیعشده به تیمها امکان میدهد که دادهها را مانند یک محصول (Data-as-a-Product) مدیریت کنند و بدون نیاز به وابستگی به تیمهای مرکزی، دسترسی و تحلیل دادههای مورد نیاز خود را انجام دهند.
تفاوت دیتا مش با معماری سنتی دادهها
در معماریهای سنتی مانند Data Lake و Data Warehouse، دادهها به صورت متمرکز در یک پایگاه داده مرکزی جمعآوری و ذخیره میشوند. این رویکرد به دلیل ماهیت متمرکز خود، مشکلات زیر را به همراه دارد:
- افزایش بار روی تیمهای مرکزی: همه مسئولیتهای مدیریت و نگهداری دادهها بر عهده یک تیم واحد (معمولاً تیم IT) است، که این امر باعث ایجاد گلوگاه در فرایند دسترسی به دادهها میشود.
- کاهش سرعت و انعطافپذیری: زمانی که تیمها برای دریافت و تحلیل دادهها باید از یک تیم متمرکز درخواست کنند، سرعت پاسخدهی کاهش یافته و تصمیمگیری به تأخیر میافتد.
- مشکلات مقیاسپذیری: افزایش حجم دادهها و تنوع آنها، کارایی معماریهای سنتی را به مرور زمان کاهش میدهد و ارتقاء آنها نیازمند هزینههای بالاست.
در مقابل، دیتا مش از رویکردی توزیعشده استفاده میکند که در آن، هر واحد دادهای (Data Domain) به صورت مستقل توسط تیمی که بیشترین تخصص در آن زمینه را دارد، مدیریت میشود. این ساختار دارای ویژگیهای زیر است:
- توزیع مسئولیتها: مسئولیت نگهداری، کیفیت و دسترسیپذیری دادهها به تیمهای مختلف در سراسر سازمان واگذار میشود. هر تیم دادههای خود را به عنوان یک «محصول» مدیریت میکند و موظف است تا دادهها را در دسترس واحدهای دیگر نیز قرار دهد.
- افزایش سرعت و مقیاسپذیری: به دلیل ساختار توزیعشده، تیمها میتوانند دادههای خود را سریعتر پردازش کنند و در مقیاسهای بزرگتر توسعه دهند. این امر باعث میشود که سازمانها بدون ایجاد گلوگاه، به راحتی دادههای خود را در مقیاس وسیعتر مدیریت کنند.
- توانمندسازی تیمها: به جای اینکه تیمها منتظر دریافت دادهها از تیمهای مرکزی باشند، میتوانند با دسترسی مستقیم به دادههای مورد نیاز، سریعتر تصمیمگیری کنند و نوآوری را بهبود بخشند.
چرا دیتا مش برای سازمانها ضروری است؟
دیتا مش نه تنها به مشکلات مقیاسپذیری و پیچیدگی معماریهای سنتی پاسخ میدهد، بلکه به کسبوکارها اجازه میدهد تا فرهنگ دادهمحوری را در سازمان خود تقویت کنند. هر تیم مسئولیت دادههای خود را بر عهده دارد، که این امر باعث ارتقای کیفیت و دسترسیپذیری دادهها میشود و در نهایت، سازمان را در مسیر تحول دیجیتال و تصمیمگیری دادهمحور یاری میدهد.
چهار اصل کلیدی دیتا مش
مش دادهها بر پایه چهار اصل کلیدی طراحی شده است که هرکدام به گونهای سازمان را در مدیریت دادهها به شیوهای مدرن و کارآمد هدایت میکنند. این اصول به کسبوکارها کمک میکند تا با تفکیک وظایف، ایجاد شفافیت، و ارتقای کیفیت دادهها، ارزش واقعی دادهها را بهعنوان یک دارایی استراتژیک به حداکثر برسانند. در این بخش، این چهار اصل را به تفصیل بررسی میکنیم:
۱. مالکیت توزیعشده دادهها (Domain-Oriented Ownership)
در رویکرد سنتی، مدیریت و پردازش دادهها به طور متمرکز بر عهده یک تیم IT قرار دارد. اما در مدل دیتا مش (مش دادهها)، مالکیت دادهها به تیمهای تخصصی در هر بخش یا واحد سازمانی واگذار میشود. به عبارت دیگر، هر دامنه دادهای (Data Domain) مانند واحد مالی، منابع انسانی یا بازاریابی، مسئولیت دادههای خود را به عهده دارد.
این اصل باعث میشود که تیمهای عملیاتی، مالک دادههای مربوط به حوزه کاری خود باشند و بدون نیاز به وابستگی به یک تیم متمرکز، دادهها را تولید، پردازش و منتشر کنند. نتیجه این امر، کاهش گلوگاههای مدیریتی و افزایش انعطافپذیری در دسترسی به دادههاست. همچنین، این مدل باعث میشود تا هر تیم نسبت به کیفیت، دقت و بهروز بودن دادههای خود پاسخگو باشد، که در نهایت به بهبود کیفیت کلی دادهها در سراسر سازمان منجر میشود.
۲. معماری دادهها به عنوان یک محصول (Data as a Product)
در دیتا مش، دادهها صرفاً منابع خام یا اطلاعات ثبتشده نیستند؛ بلکه به عنوان یک محصول نهایی در نظر گرفته میشوند که باید دارای کیفیت بالا، مستندات کامل، و قابلیت دسترسی آسان باشد. این رویکرد بر این اصل تأکید دارد که دادهها باید با ذهنیت مشتریمحور توسعه یابند. به بیان دیگر، تیمها باید دادهها را به گونهای طراحی و مدیریت کنند که کاربران نهایی (چه واحدهای داخلی سازمان و چه ذینفعان خارجی) بتوانند به راحتی از آنها استفاده کنند.
تبدیل دادهها به عنوان یک محصول، باعث میشود که تیمها بر روی قابلیت اعتماد، دقت، و امنیت دادهها تمرکز کنند و این ویژگیها را مانند یک محصول واقعی بهبود دهند. در نتیجه، دادهها نه تنها برای تیمهای داخلی، بلکه برای تمام کاربران سازمانی قابل استفاده خواهند بود. هر تیم باید دادههای خود را مانند یک سرویس با ارزش افزوده ارائه دهد، به طوری که سایر تیمها نیز بتوانند به طور مستقیم از این دادهها در تصمیمگیریهای خود بهرهمند شوند .
۳. قابلیت کشف و دسترسی (Data Discoverability)
یکی از چالشهای اصلی در مدیریت دادهها، پیدا کردن و دسترسی به دادههای مورد نیاز است. در مدل سنتی، کاربران اغلب باید درخواستهای پیچیدهای به تیم IT ارائه دهند تا به دادههای مورد نظر خود دسترسی پیدا کنند. اما در مدل دیتا مش، قابلیت کشف و دسترسی (Discoverability) به عنوان یکی از اصول کلیدی مطرح میشود.
این اصل به معنای آن است که هر دادهای باید به صورت شفاف، مستند و قابل دسترسی باشد، به طوری که کاربران نهایی بتوانند به راحتی دادهها را پیدا و از آنها استفاده کنند. برای دستیابی به این هدف، از ابزارها و فناوریهای جدیدی مانند کاتالوگهای داده (Data Catalogs) استفاده میشود که تمام دادههای موجود در سازمان را بهصورت فهرستبندی و دستهبندیشده در اختیار کاربران قرار میدهند. به این ترتیب، تیمها میتوانند دادههای مربوط به هر حوزه را به سرعت پیدا کرده و در پروژهها و تحلیلهای خود از آنها استفاده کنند .
۴. مدیریت سراسری (Federated Computational Governance)
یکی از چالشهای بزرگ در مدیریت دادهها در ساختارهای توزیعشده، ایجاد توازن بین کنترل مرکزی و آزادی واحدهای مختلف است. مدیریت سراسری در دیتا مش به گونهای طراحی شده است که هم کنترل مرکزی برای اطمینان از امنیت و انطباق دادهها حفظ شود و هم تیمهای عملیاتی آزادی لازم را برای مدیریت دادههای خود داشته باشند.
این مدل ترکیبی به معنای استفاده از سیاستها و قوانین مرکزی برای کنترل دادهها و در عین حال، ارائه ابزارها و زیرساختهای لازم به تیمهای عملیاتی برای پیادهسازی این قوانین است. به عنوان مثال، ممکن است یک تیم مسئول ایجاد استانداردهای امنیتی باشد، در حالی که هر تیم عملیاتی باید این استانداردها را در دامنه دادهای خود پیادهسازی و مدیریت کند.
این رویکرد باعث میشود که سازمانها بتوانند انطباقپذیری و امنیت را در سطح کلان حفظ کنند و در عین حال، به تیمها اجازه دهند تا به صورت مستقل و منعطف دادههای خود را مدیریت کنند. در نهایت، این توازن میان کنترل مرکزی و استقلال محلی، بهرهوری کلی را در سطح سازمان بهبود میبخشد .

مزایای استفاده از دیتا مش در سازمانها
دیتا مش با ارائه رویکردی جدید به مدیریت دادهها، میتواند به عنوان یک تحول اساسی در سازمانها عمل کند. این رویکرد، مزایای متعددی را به همراه دارد که سازمانها را قادر میسازد تا به طور موثرتری از دادهها استفاده کنند و عملکرد خود را بهبود بخشند. در ادامه به برخی از مزایای کلیدی مش دادهها میپردازیم:
۱. کاهش وابستگی به تیمهای مرکزی
یکی از بزرگترین مشکلات در معماریهای سنتی دادهای، تمرکز زیاد بر روی تیمهای مرکزی است که باعث ایجاد گلوگاههای مدیریتی میشود. در این مدلها، تمام درخواستها برای دسترسی، تجزیهوتحلیل یا تغییرات در دادهها باید از طریق یک تیم IT متمرکز انجام شود که این امر میتواند به کاهش سرعت واکنش و افزایش تاخیر در پردازش دادهها منجر شود.
اما در مدل دیتا مش (مش دادهها)، هر تیم عملیاتی مالکیت و مدیریت دادههای مربوط به خود را بر عهده دارد. این ساختار وابستگی به تیمهای مرکزی را کاهش میدهد و تیمها میتوانند به سرعت به دادههای مورد نیاز خود دسترسی پیدا کنند. به عنوان مثال، تیم بازاریابی میتواند بدون نیاز به درخواست از تیم IT، دادههای مربوط به مشتریان را بررسی و تحلیل کند. این رویکرد باعث میشود که سازمانها گلوگاههای رایج را حذف کرده و سرعت تصمیمگیری خود را به طور قابل توجهی افزایش دهند.
۲. افزایش چابکی سازمانی
در محیط کسبوکاری که به سرعت در حال تغییر است، چابکی سازمانی یکی از عوامل کلیدی موفقیت به شمار میرود. ساختار مش دادهها به تیمها اجازه میدهد تا با تغییرات بازار و نیازمندیهای جدید به سرعت هماهنگ شوند. به دلیل اینکه هر تیم به دادههای خود دسترسی مستقیم دارد و میتواند تغییرات لازم را به سرعت اعمال کند، سازمانها قادر خواهند بود تا واکنش سریعتری به تغییرات بازار نشان دهند.
علاوه بر این، این مدل باعث میشود که تیمها بتوانند آزمایشهای جدید را با دادههای خود انجام دهند و نوآوریهای بیشتری را در فرآیندها و محصولات خود اعمال کنند. در واقع، مش دادهها نه تنها سرعت واکنش به تغییرات را افزایش میدهد، بلکه توانمندی تصمیمگیری را در سطح سازمانی بهبود میبخشد و تیمها را قادر میسازد تا استراتژیهای دادهمحور را سریعتر پیادهسازی کنند.
۳. مدیریت دادهها در مقیاس بزرگتر
یکی از بزرگترین چالشها در مدیریت دادهها در مقیاس بزرگ، مقیاسپذیری معماریهای سنتی است. به طور معمول، افزایش حجم دادهها و تنوع آنها باعث میشود که عملکرد و کارایی سیستمهای متمرکز کاهش یابد. اما مش دادهها این مشکل را با رویکرد توزیعشده خود حل میکند. در این مدل، هر دامنه دادهای (Data Domain) به صورت مستقل دادههای خود را مدیریت میکند و این امر به سازمانها اجازه میدهد تا دادهها را در مقیاس بزرگتر و بدون افت کیفیت مدیریت کنند.
این ساختار به سازمانها کمک میکند که حتی در صورت رشد قابل توجه حجم دادهها، همچنان بتوانند دادهها را به صورت موثر و کارآمد مدیریت کنند. به عنوان مثال، یک شرکت چندملیتی با واحدهای عملیاتی متعدد در نقاط مختلف جهان، میتواند دادههای خود را به صورت توزیعشده در هر واحد مدیریت کند، بدون اینکه نیاز به یک مرکز داده متمرکز باشد.
۴. تسهیل دسترسی به دادهها
یکی از مهمترین مزایای مش دادهها، تسهیل دسترسی به دادهها برای تمامی تیمها در سازمان است. در مدلهای سنتی، اغلب دسترسی به دادهها محدود به تیمهای خاصی میشود و سایر تیمها باید برای دریافت دادههای مورد نیاز خود درخواستهایی را به تیمهای مرکزی ارسال کنند. این امر نه تنها باعث کاهش کارایی میشود، بلکه مانع نوآوری نیز میگردد.
اما در مدل مش دادهها، تمامی دادهها به صورت مستند و فهرستبندیشده در اختیار تیمها قرار میگیرد. این ویژگی باعث میشود که هر تیم بتواند به سرعت و با سهولت دادههای مورد نیاز خود را پیدا کند و از آنها برای تصمیمگیریهای روزانه و استراتژیک استفاده کند. علاوه بر این، قابلیت کشفپذیری دادهها (Discoverability) باعث میشود که سازمانها بتوانند به سرعت دادههای جدید را شناسایی و به آنها دسترسی پیدا کنند، که این امر شفافیت و کارایی کلی را در سازمان افزایش میدهد.
چالشها و موانع پیادهسازی دیتا مش
اگرچه مش دادهها (Data Mesh) مزایای زیادی دارد، اما پیادهسازی آن در سازمانها بدون چالش نیست. سازمانها برای بهرهبرداری کامل از این رویکرد نیاز به درک عمیقی از پیچیدگیهای فنی و فرهنگی دارند. در این بخش، به بررسی چالشهای اصلی در پیادهسازی مش دادهها میپردازیم:
۱. نیاز به تغییر فرهنگ سازمانی
یکی از بزرگترین موانع در پیادهسازی مش دادهها، تغییر فرهنگ سازمانی است. در معماریهای سنتی، تیمهای عملیاتی معمولاً نقش محدودی در مدیریت دادهها دارند و بیشتر به عنوان مصرفکننده دادهها شناخته میشوند. اما در مدل مش دادهها، مالکیت و مدیریت دادهها به تیمهای تخصصی واگذار میشود. این به معنای آن است که تیمها باید مسئولیت کامل برای کیفیت، دسترسی و مستندات دادههای خود را بر عهده بگیرند.
این تغییر فرهنگی نیازمند آموزش و توسعه مهارتهای جدید برای تیمهاست تا بتوانند از یک مصرفکننده داده به مالک داده تبدیل شوند. همچنین، تیمها باید یاد بگیرند که چگونه دادههای خود را به گونهای مدیریت کنند که برای دیگر تیمهای سازمان نیز قابل استفاده باشد. این فرآیند ممکن است مقاومت فرهنگی و تغییرات سازمانی گسترده را به دنبال داشته باشد، به ویژه در سازمانهایی که به مدت طولانی از معماریهای سنتی دادهها استفاده کردهاند.
۲. پیچیدگی فنی
پیادهسازی مش دادهها نیازمند معماریهای جدید و پیچیدهای است که ممکن است برای بسیاری از سازمانها چالشبرانگیز باشد. در حالی که معماریهای سنتی مانند دیتا ویرهاوس (Data Warehouse) و دیتا لیک (Data Lake) تمرکز بر ایجاد یک مخزن مرکزی دارند، مش دادهها نیازمند یکپارچگی در بین دامنههای مختلف دادهای و پیادهسازی توزیعشدهای است که به راحتی قابل مدیریت نباشد.
این امر به معنای استفاده از زیرساختها و ابزارهای نوین است که توانایی مدیریت دادهها در سطح توزیعشده را فراهم کنند. علاوه بر این، تیمها نیاز به مهارتهای تخصصی در زمینههایی مانند مدلسازی دادهها، ایجاد APIها، و امنیت دادهها دارند تا بتوانند دادههای خود را به صورت مستقل مدیریت و به دیگران ارائه کنند. همچنین، برای اطمینان از اینکه دادهها در سراسر سازمان به درستی جریان پیدا میکنند، باید استانداردهای ارتباطی و هماهنگی فنی بین تیمها برقرار شود که این کار به مدیریت پیچیدگی بالایی نیاز دارد.
۳. مشکلات امنیت و انطباق
در مدلهای سنتی متمرکز، مدیریت امنیت و انطباق با مقررات دادهها اغلب به طور مستقیم توسط تیم IT مرکزی انجام میشود. اما در مدل مش دادهها، که مدیریت دادهها به صورت توزیعشده به تیمهای مختلف واگذار شده است، حفظ امنیت دادهها و اطمینان از انطباق با مقررات میتواند یک چالش اساسی باشد.
برای مثال، قوانین و مقرراتی مانند GDPR (مقررات عمومی حفاظت از دادهها) یا CCPA (قانون حفظ حریم خصوصی مصرفکنندگان کالیفرنیا) میتوانند در محیطهای توزیعشده پیچیدهتر اجرا شوند، زیرا تیمهای مختلف مسئولیت بخشهای مختلف داده را بر عهده دارند. این به معنای آن است که سازمانها باید سیاستهای امنیتی و انطباقی جامعی را در سطح سازمان طراحی کنند و اطمینان حاصل کنند که تمامی تیمها این سیاستها را رعایت میکنند.
برای مقابله با این چالش، سازمانها میتوانند از مدیریت سراسری محاسباتی (Federated Computational Governance) استفاده کنند که یک مدل ترکیبی است و به هر تیم اجازه میدهد تا سیاستهای امنیتی را بر اساس قوانین کلی پیادهسازی کند. این مدل تضمین میکند که کنترل مرکزی بر روی استانداردهای امنیتی حفظ میشود، در حالی که تیمهای عملیاتی استقلال لازم برای مدیریت دادههای خود را دارند.

بهترین رویکردها برای پیادهسازی دیتا مش
پیادهسازی موفقیتآمیز مش دادهها (Data Mesh) نیازمند داشتن یک استراتژی مشخص و گامهای برنامهریزیشده است. سازمانها باید رویکردی مرحلهبهمرحله و متمرکز بر بهینهسازی فرآیندها اتخاذ کنند تا بتوانند از مزایای کامل این معماری بهرهمند شوند. در این بخش، به بررسی بهترین رویکردهایی که میتواند پیادهسازی مش دادهها را بهبود بخشد، میپردازیم:
۱. انتخاب تیمهای پیشرو برای آزمایش اولیه
شروع یک پروژه مش دادهها در کل سازمان میتواند پیچیده و مخاطرهآمیز باشد، به ویژه اگر سازمان تجربه کافی در مدیریت دادههای توزیعشده نداشته باشد. بنابراین، بهترین راهکار این است که پیادهسازی را با چند تیم مشخص و کوچکتر آغاز کنید. این تیمها به عنوان تیمهای پیشرو عمل میکنند که میتوانند رویکردهای جدید را آزمایش کرده و بازخوردهای عملی ارائه دهند.
انتخاب این تیمها باید با دقت انجام شود. بهتر است تیمهایی انتخاب شوند که از آمادگی لازم برای پذیرش تغییرات برخوردارند و دارای تجربه کافی در مدیریت دادهها هستند. همچنین، لازم است که اهداف اولیه و معیارهای موفقیت به وضوح تعریف شود تا سازمان بتواند نتایج این پیادهسازی آزمایشی را ارزیابی کند و از آنها برای گسترش مدل مش دادهها به سایر بخشها استفاده کند.
۲. توسعه ابزارهای مشترک برای مدیریت دادهها
یکی از اصول مهم در پیادهسازی موفق مش دادهها، ایجاد ابزارهای مشترک و توسعه استانداردهای یکپارچه برای تمامی تیمها است. از آنجا که در این مدل، دادهها به صورت توزیعشده در تیمهای مختلف مدیریت میشوند، داشتن ابزارها و استانداردهای مشترک برای مواردی مانند دسترسی، مستندسازی، مدیریت کیفیت دادهها و امنیت ضروری است.
توسعه این ابزارها میتواند به هماهنگی بیشتر بین تیمها کمک کند و اطمینان حاصل کند که تمامی تیمها از روشهای یکسان برای مدیریت دادهها استفاده میکنند. به عنوان مثال، استفاده از پلتفرمهای مشترک برای مدیریت دادهها مانند Apache Kafka یا DataHub میتواند قابلیت همکاری بین تیمها را افزایش دهد و امکان همگامسازی سریعتر دادهها را فراهم آورد.
همچنین، ایجاد یک کتابخانه دادهای (Data Catalog) به عنوان منبع مرکزی اطلاعات میتواند به تیمها کمک کند تا به راحتی دادهها را کشف و استفاده کنند. این رویکرد به کاهش پراکندگی دادهها و افزایش شفافیت در سازمان منجر میشود، بهطوریکه هر تیم میداند که چگونه و کجا باید به دادههای مورد نیاز خود دسترسی پیدا کند.
۳. توجه به مقیاسپذیری
مش دادهها به طور ذاتی برای مدیریت دادهها در مقیاس بزرگ طراحی شده است، اما برای بهرهبرداری کامل از این مزیت، سازمانها باید مقیاسپذیری را از همان ابتدا در نظر بگیرند. این به معنای طراحی معماریهایی است که میتواند با رشد حجم دادهها و افزایش تعداد تیمها بدون افت کارایی یا افزایش پیچیدگی، گسترش یابد.
برای دستیابی به این هدف، سازمانها باید به موارد زیر توجه کنند:
- استفاده از زیرساختهای ابری: بهرهگیری از پلتفرمهای ابری مانند AWS، Azure یا Google Cloud میتواند به سازمانها کمک کند تا به سرعت مقیاس خود را افزایش داده و از ابزارهای مدیریت توزیعشده برای دادهها استفاده کنند.
- استانداردسازی مدلهای دادهای: اطمینان حاصل شود که تمامی تیمها از قواعد و الگوهای یکسانی برای مدلسازی دادهها استفاده میکنند تا قابلیت همکاری بین دامنههای دادهای حفظ شود.
- مانیتورینگ و نظارت مستمر: استفاده از ابزارهای نظارت بر عملکرد و مانیتورینگ (مانند Prometheus یا Grafana) برای بررسی عملکرد سیستم و شناسایی مشکلات احتمالی پیش از آنکه تبدیل به یک بحران شوند.
این رویکردها به سازمانها کمک میکند تا به طور مؤثری مش دادهها را در سطح بزرگ پیادهسازی کنند و از آن برای بهینهسازی جریان دادهها و تصمیمگیریهای سریعتر استفاده کنند.
نتیجهگیری: آینده مش دادهها
با پیشرفت روزافزون تکنولوژی و افزایش حجم و تنوع دادهها، مش دادهها (Data Mesh) به یک مدل نوآورانه و ضروری در مدیریت دادهها تبدیل شده است. این رویکرد نه تنها به سازمانها کمک میکند تا از چالشهای موجود در ساختارهای سنتی فراتر بروند، بلکه به آنها امکان میدهد که با سرعت بیشتری به تغییرات بازار و نیازهای مشتریان پاسخ دهند.
نقش مش دادهها در تحولات آینده سازمانها
آینده مش دادهها به وضوح در تحولات بزرگ فناوری و نیازهای تجاری نهفته است. با توزیع مسئولیت مدیریت دادهها بین تیمهای مختلف، سازمانها قادر خواهند بود تا به سرعت و کارآمدی بیشتری به تجزیه و تحلیل دادهها بپردازند. این رویکرد باعث میشود که دادهها به صورت محصولی در نظر گرفته شوند که برای نیازهای خاص هر بخش از سازمان طراحی و مدیریت میشود. به همین دلیل، سازمانها میتوانند بهرهوری و کارایی خود را افزایش دهند و از دادهها به عنوان منبعی برای ایجاد ارزش واقعی استفاده کنند .
مش دادهها به عنوان ابزاری برای تقویت تصمیمگیری
یکی از بزرگترین مزایای مش دادهها این است که به سازمانها این امکان را میدهد که بینشهای عمیق و دقیقتری از دادههای خود استخراج کنند. با این روش، تیمها میتوانند به اطلاعات مورد نیاز به سرعت و به آسانی دسترسی پیدا کنند و این امر باعث افزایش چابکی در تصمیمگیریهای کلیدی میشود.
همچنین، مش دادهها به سازمانها کمک میکند تا فرآیندهای تصمیمگیری را بهبود بخشند و آنها را از حالت واکنشی به وضعیت پیشگیرانه تغییر دهند. با در دست داشتن دادههای به روز و مستند، مدیران میتوانند به تصمیمگیریهای استراتژیک و مبتنی بر دادههای واقعی بپردازند و از این طریق مزیت رقابتی قابل توجهی نسبت به رقبای خود به دست آورند .
در نهایت، به نظر میرسد که مش دادهها به عنوان یک رویکرد تحولی در مدیریت دادهها، مسیرهای جدیدی را برای سازمانها باز میکند و آنها را در استفاده مؤثر از دادهها و تصمیمگیریهای کلیدی یاری میکند. با توجه به اینکه دادهها به قلب استراتژیهای تجاری تبدیل میشوند، سازمانهایی که زودتر به این مدل روی آورند، قطعاً در آیندهای نزدیک موفقتر خواهند بود .

ابزارها



























محمدمهدی صفایی میگه:
مظاهری میگه:
Mz میگه: