در عصر حاضر، که از آن به عنوان «انقلاب صنعتی چهارم» یاد میشود، دادهها به ارزشمندترین دارایی سازمانها تبدیل شدهاند. دیگر نمیتوان موفقیت را تنها با تکیه بر شهود، تجربه یا حتی گزارشهای سنتی تضمین کرد. رهبران کسبوکار امروز با یک واقعیت غیرقابل انکار روبرو هستند: یا باید دادهها را به خدمت بگیرند، یا در رقابت با کسانی که این کار را میکنند، به حاشیه رانده شوند. در قلب این تحول استراتژیک، مفهومی قدرتمند به نام تحلیل کلان دادهقرار دارد؛ فرآیندی که دیگر یک گزینه لوکس فناوریمحور نیست، بلکه یک ضرورت انکارناپذیر برای بقا و رشد پایدار است. تحلیل کلان داده به سازمانها این امکان را میدهد که از حجم عظیمی از دادههای متنوع و سریع که از منابع مختلفی مانند شبکههای اجتماعی، حسگرهای اینترنت اشیاء (IoT)، تراکنشهای مشتریان و لاگهای سیستمی سرچشمه میگیرند، بینشهای تجاری (Business Insights) عمیق و کاربردی استخراج کنند.
این مقاله برای مدیران و استراتژیستهایی طراحی شده است که به دنبال درک عمیقتری از این حوزه هستند و میخواهند بدانند چگونه میتوانند از قدرت تحلیل کلان داده برای ایجاد مزیت رقابتی پایدار بهرهبرداری کنند. ما از تعاریف اولیه فراتر رفته و به بررسی کاربردهای پیشرفته، تقاطع آن با هوش مصنوعی (AI) و هوش تجاری (BI)، چالشهای پیادهسازی و نقشه راه موفقیت خواهیم پرداخت. هدف ما این است که شما، به عنوان رهبر سازمان، دیدگاهی شفاف و راهبردی نسبت به این پدیده تحولآفرین پیدا کنید و بتوانید با اطمینان، اولین یا گام بعدی خود را در این مسیر بردارید. این دیگر بحثی در مورد «اگر» نیست، بلکه در مورد «چگونه» و «چه زمانی» است.
تحلیل کلان داده چیست وچطور از آن استفاده میکنند؟
فهرست مطالب
- 1 تحلیل کلان داده چیست وچطور از آن استفاده میکنند؟
- 2 تحلیل کلان داده از کجا آمده است؟
- 3 واژه شناسی و درک دقیق اصطلاحات در حوزه تحلیل کلان داده
- 4 کاربردهای تحول آفرین تحلیل کلان داده در صنایع مختلف
- 5 پیادهسازی تحلیل کلان داده: چه ساختار سازمانی برای موفقیت لازم است؟
- 6 تیم های کلیدی در اکوسیستم تحلیل کلان داده
- 7 بهترین شیوه های پیاده سازی تحلیل کلان داده
- 8 گامبهگام تا موفقیت: مراحل اجرای یک پروژه تحلیل کلان داده
- 9 رایجترین چالش ها در مسیر تحلیل کلان داده
- 10 مزایا و فرصت های طلایی تحلیل کلان داده برای کسب و کار شما
- 11 معایب و ریسک های بالقوه تحلیل کلان داده
- 12 ابزارها و پلتفرم های قدرتمند در تحلیل کلان داده
- 13 افق های آینده: ترندهای نوظهور و جهت گیریهای آینده تحلیل کلان داده
- 14 چگونه هوش مصنوعی، قدرت تحلیل کلان داده را چندبرابر میکند؟
- 15 چکلیست نهایی: آیا سازمان شما برای بهرهبرداری از تحلیل کلان داده آماده است؟
- 16 نقش ما به عنوان مشاور: چگونه میتوانیم شما را در مسیر تحلیل کلان داده همراهی کنیم؟
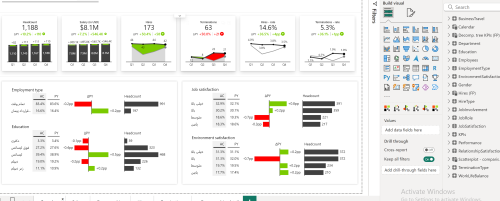
- 16.1 داشبورد منابع انسانی – HR Analytics in Power BI
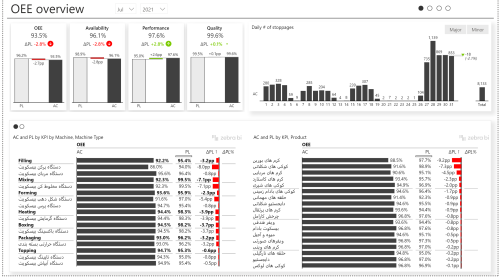
- 16.2 داشبورد تولید، برنامه ریزی تولید، نگهداری و تعمیرات
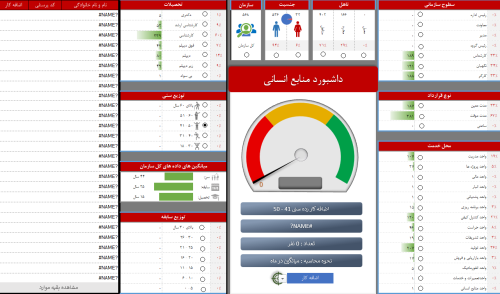
- 16.3 قالب داشبورد شاخص های مدیریت عملکرد منابع انسانی
- 16.4 قالب اکسل داشبورد مدیریت منابع انسانی
- 16.5 داشبورد شاخص های کلیدی عملکرد تولید و برنامه ریزی | KPI
- 16.6 داشبورد فروش و بازاریابی – Sales Dashboard in Power BI
- 16.7 اکسل تقویم ۱۴۰۵
- 16.8 داشبورد کالاهای مصرفی تندگردش – Brand and Product Portfolio Analysis Power BI Template
- 16.9 بسته کامل شرح شغلی برای سازمان ها و شرکت ها
- 16.10 بسته کامل فرم ها، شاخص ها و شرح شغل های کسب و کاری
- 16.11 قالب اکسل داشبورد مدیریت کارکنان
- 16.12 داشبورد مالی و بهای تمام شده – Working Capital in Power BI
برای درک عمیق اهمیت استراتژیک تحلیل کلان داده، ابتدا باید تعریف دقیق و جامعی از آن ارائه دهیم. تحلیل کلان داده فرآیند بررسی مجموعههای دادهای بسیار بزرگ و پیچیده (معروف به دادههای حجیم یا Big Data) است که روشهای سنتی پردازش و تحلیل داده از مدیریت آنها عاجزند. هدف نهایی این فرآیند، کشف الگوهای پنهان، همبستگیهای ناشناخته، روندهای بازار، ترجیحات مشتریان و سایر اطلاعات مفیدی است که میتواند به سازمانها در اتخاذ تصمیمات هوشمندانهتر کمک کند. این مفهوم معمولاً با «پنج V» تعریف میشود که ابعاد مختلف آن را روشن میسازد:
- حجم (Volume): اشاره به مقیاس عظیم دادهها دارد که اغلب در حد ترابایت، پتابایت و حتی اگزابایت است.
- سرعت (Velocity): به سرعت بالای تولید و پردازش دادهها اشاره دارد که نیازمند تحلیل در لحظه (Real-time) یا نزدیک به لحظه است.
- تنوع (Variety): دادهها دیگر فقط محدود به جداول ساختاریافته در پایگاههای داده نیستند. تحلیل کلان داده با دادههای بدون ساختار (مانند متن، ویدئو، صوت) و نیمهساختاریافته (مانند فایلهای XML) نیز سروکار دارد.
- صحت (Veracity): به عدم قطعیت و قابلیت اطمینان دادهها اشاره دارد. اطمینان از کیفیت و دقت دادهها یک چالش بزرگ در این حوزه است.
- ارزش (Value): مهمترین بُعد که به معنای توانایی تبدیل دادههای خام به ارزش تجاری ملموس است. تحلیل کلان داده بدون ایجاد ارزش، تنها یک هزینه گزاف خواهد بود.
اما چه کسانی، کجا و چه زمانی از آن بهره میبرند؟ پاسخ کوتاه این است: «همه، همهجا و همیشه». از یک استارتاپ تجارت الکترونیک که رفتار کلیک کاربران را برای بهینهسازی وبسایت خود تحلیل میکند، تا یک شرکت تولیدی عظیم که دادههای حسگرهای ماشینآلات را برای پیشبینی خرابیها (Predictive Maintenance) به کار میگیرد. از یک بانک که تراکنشها را در لحظه برای شناسایی تقلب تحلیل میکند، تا یک بیمارستان که سوابق پزشکی را برای یافتن الگوهای درمانی مؤثرتر بررسی مینماید. تحلیل کلان داده دیگر محدود به غولهای فناوری مانند گوگل و آمازون نیست؛ بلکه به یک ابزار استراتژیک برای هر سازمانی تبدیل شده که به دنبال درک عمیقتر از بازار، مشتریان و عملیات داخلی خود است.

تحلیل کلان داده از کجا آمده است؟
اگرچه واژه «Big Data» در اوایل دهه ۲۰۰۰ رایج شد، اما ریشههای مفهومی تحلیل کلان داده به دههها قبل بازمیگردد. تاریخچه این حوزه را میتوان به عنوان یک تکامل تدریجی در توانایی انسان برای جمعآوری، ذخیرهسازی و تحلیل دادهها مشاهده کرد. در دهههای ۱۹۶۰ و ۱۹۷۰، با ظهور اولین مراکز داده و پایگاههای داده رابطهای، کسبوکارها شروع به تحلیل دادههای ساختاریافته خود کردند. این دوران، سرآغاز هوش تجاری سنتی بود که بر گزارشگیری از وقایع گذشته تمرکز داشت.
نقطه عطف کلیدی در اواخر دهه ۱۹۹۰ و اوایل دهه ۲۰۰۰ با ظهور اینترنت و انفجار دادههای تولید شده توسط کاربران رخ داد. شرکتهایی مانند یاهو و گوگل با چالشهایی روبرو شدند که سیستمهای سنتی قادر به پاسخگویی به آنها نبودند. این امر منجر به توسعه فناوریهای نوآورانهای مانند «MapReduce» و «Google File System» توسط گوگل شد که بعدها الهامبخش پروژههای متنبازی مانند «Apache Hadoop» گردید. این فناوریها برای پردازش موازی و توزیعشده حجم عظیمی از دادهها بر روی خوشههایی از کامپیوترهای معمولی طراحی شده بودند و عملاً سنگ بنای زیرساختهای مدرن تحلیل کلان داده را گذاشتند.
در سال ۲۰۰۱، «داگ لینی»، تحلیلگر موسسه «گارتنر»، برای اولین بار چالشها و فرصتهای رشد داده را در قالب سه بُعد اصلی حجم، سرعت و تنوع (3Vs) تعریف کرد که به شالوده اصلی درک مفهوم دادههای حجیم تبدیل شد. از آن زمان به بعد، با ظهور رسانههای اجتماعی، دستگاههای موبایل و اینترنت اشیاء، ابعاد این مفهوم گستردهتر شد و تحلیل کلان داده از یک چالش فنی به یک اولویت استراتژیک برای کسبوکارها در سراسر جهان تبدیل گردید. این سیر تکاملی نشان میدهد که تحلیل کلان داده یک پدیده ناگهانی نیست، بلکه نتیجه دههها تلاش برای استخراج دانش از اقیانوس رو به رشد دادههاست.
واژه شناسی و درک دقیق اصطلاحات در حوزه تحلیل کلان داده
ورود به دنیای تحلیل کلان داده مستلزم درک دقیق تفاوتهای ظریف میان اصطلاحات مرتبطی است که اغلب به جای یکدیگر استفاده میشوند. برای مدیران و استراتژیستها، شناخت این تمایزها برای تدوین یک استراتژی داده منسجم و مؤثر حیاتی است. در ادامه، به بررسی و مقایسه مفاهیم کلیدی در این اکوسیستم میپردازیم.
تفاوت تحلیل کلان داده با هوش تجاری (BI)
هوش تجاری (Business Intelligence) و تحلیل کلان داده هر دو با هدف کمک به تصمیمگیری بهتر از طریق دادهها عمل میکنند، اما تفاوتهای بنیادین دارند. هوش تجاری عمدتاً به گذشته و حال میپردازد. این حوزه بر روی دادههای ساختاریافته و داخلی (مانند دادههای فروش و مالی) تمرکز دارد و از طریق داشبوردها و گزارشهای استاندارد به سوالاتی مانند «چه اتفاقی افتاد؟» و «چرا اتفاق افتاد؟» پاسخ میدهد. به عبارت دیگر، BI توصیفی و تشخیصی است. در مقابل، تحلیل کلان داده نگاهی به آینده دارد. این حوزه با انواع دادهها (ساختاریافته، نیمهساختاریافته و بدون ساختار) از منابع داخلی و خارجی سروکار دارد و با استفاده از تکنیکهای پیشرفته آماری و یادگیری ماشین (Machine Learning) به سوالات پیشبینانه («چه اتفاقی خواهد افتاد؟») و تجویزی («چه کاری باید انجام دهیم؟») پاسخ میدهد. BI به شما میگوید که کدام محصول پرفروشترین بوده است، اما تحلیل کلان داده به شما میگوید که کدام مشتریان به احتمال زیاد در آینده آن محصول را خواهند خرید و بهترین پیشنهاد برای آنها چیست.
تمایز تحلیل کلان داده از علم داده
علم داده (Data Science) یک حوزه میانرشتهای گستردهتر است که تحلیل کلان داده بخشی از آن محسوب میشود. علم داده ترکیبی از آمار، علوم کامپیوتر و دانش حوزه کسبوکار است که هدف آن استخراج دانش و بینش از دادهها در هر شکل و اندازهای است. یک «دانشمند داده» (Data Scientist) ممکن است بر روی یک پروژه تحلیل کلان داده کار کند، اما ممکن است بر روی یک مجموعه داده کوچک با الگوریتمهای پیچیده نیز کار کند. تحلیل کلان داده به طور خاص به چالشهای ناشی از حجم، سرعت و تنوع دادهها میپردازد و نیازمند زیرساختها و ابزارهای تخصصی (مانند Hadoop و Spark) است. میتوان گفت علم داده «چتر» مفهومی است و تحلیل کلان داده یکی از مهمترین و چالشیترین «کاربردهای» زیر این چتر است.
رابطه تحلیل کلان داده و دادهکاوی
دادهکاوی (Data Mining) یکی از مراحل کلیدی در فرآیند تحلیل کلان داده است. دادهکاوی به فرآیند کشف الگوها و اطلاعات ارزشمند از دل مجموعههای داده بزرگ با استفاده از تکنیکهای آماری و الگوریتمهای کامپیوتری اطلاق میشود. به عبارت دیگر، وقتی شما یک پروژه تحلیل کلان داده را اجرا میکنید، از تکنیکهای دادهکاوی برای «استخراج» الگوهای معنادار استفاده مینمایید. برای مثال، تحلیل سبد خرید (Market Basket Analysis) برای کشف اینکه کدام محصولات معمولاً با هم خریداری میشوند، یک تکنیک کلاسیک دادهکاوی است که در مقیاس بزرگ، بخشی از یک استراتژی تحلیل کلان داده در صنعت خردهفروشی محسوب میشود. دادهکاوی «موتور» کشف است، در حالی که تحلیل کلان داده «اکوسیستم» کاملی است که این موتور را در مقیاس عظیم به کار میگیرد.

کاربردهای تحول آفرین تحلیل کلان داده در صنایع مختلف
قدرت واقعی تحلیل کلان داده زمانی آشکار میشود که از مفاهیم تئوریک فراتر رفته و به کاربردهای عملی آن در دنیای واقعی کسبوکار نگاه کنیم. این فناوری در حال بازآفرینی مدلهای کسبوکار و ایجاد مزیتهای رقابتی بیسابقه در صنایع گوناگون است. در این بخش، به بررسی نمونههای ملموس و استراتژیک از پیادهسازی تحلیل کلان داده در چند صنعت کلیدی میپردازیم تا الهامبخش شما برای یافتن فرصتهای مشابه در سازمان خودتان باشد.
کاربرد تحلیل کلان داده در صنعت خردهفروشی و تجارت الکترونیک
شاید هیچ صنعتی به اندازه خردهفروشی از تحلیل کلان داده بهره نبرده باشد. غولهایی مانند آمازون، مدل کسبوکار خود را بر پایه درک عمیق از مشتری بنا کردهاند. آنها با تحلیل تاریخچه خرید، رفتار مرور وبسایت، لیست علاقهمندیها و حتی نظرات کاربران، میتوانند محصولات را به صورت فوقالعاده شخصیسازی شده پیشنهاد دهند. این «موتورهای پیشنهاددهنده» (Recommendation Engines) که مستقیماً از نتایج تحلیل کلان داده قدرت میگیرند، بخش قابل توجهی از فروش این شرکتها را تشکیل میدهند. کاربردهای دیگر شامل قیمتگذاری پویا (Dynamic Pricing) بر اساس تقاضا و رفتار رقبا، بهینهسازی زنجیره تأمین با پیشبینی دقیق تقاضا برای هر محصول در هر منطقه جغرافیایی، و تحلیل احساسات مشتریان در شبکههای اجتماعی برای درک بازخوردها و بهبود خدمات است.
نقش استراتژیک تحلیل کلان داده در خدمات مالی و بانکداری
بخش خدمات مالی با حجم عظیمی از دادههای تراکنشی و بازار سروکار دارد که آن را به بستری ایدهآل برای تحلیل کلان داده تبدیل کرده است. یکی از حیاتیترین کاربردها، تشخیص تقلب در لحظه (Real-time Fraud Detection) است. الگوریتمهای یادگیری ماشین با تحلیل میلیونها تراکنش در ثانیه، الگوهای غیرعادی را شناسایی کرده و از تراکنشهای مشکوک قبل از وقوع خسارت جلوگیری میکنند. کاربردهای دیگر شامل ارزیابی ریسک اعتباری با استفاده از منابع داده جایگزین (مانند رفتار آنلاین)، تجارت الگوریتمی (Algorithmic Trading) که در آن مدلها بر اساس تحلیل دادههای بازار به صورت خودکار معامله میکنند، و بخشبندی پیشرفته مشتریان (Customer Segmentation) برای ارائه محصولات و خدمات مالی متناسب با نیازهای هر فرد است.
تحول نظام سلامت با قدرت تحلیل کلان داده
صنعت بهداشت و درمان در آستانه یک انقلاب دادهمحور قرار دارد. تحلیل کلان داده در این حوزه میتواند به معنای واقعی کلمه، نجاتبخش جان انسانها باشد. با تحلیل حجم عظیمی از دادههای ژنومیک، سوابق الکترونیک سلامت (EHR) و نتایج آزمایشگاهی، محققان میتوانند به سمت پزشکی شخصیسازی شده (Personalized Medicine) حرکت کنند و درمانها را متناسب با ویژگیهای ژنتیکی هر بیمار طراحی نمایند. کاربردهای دیگر شامل پیشبینی شیوع بیماریها با تحلیل دادههای شبکههای اجتماعی و گزارشهای بهداشتی، بهینهسازی مدیریت بیمارستانها با پیشبینی تعداد مراجعین و تخصیص منابع، و تسریع فرآیند کشف دارو با تحلیل نتایج آزمایشهای بالینی در مقیاس بزرگ است.
بهینهسازی تولید و زنجیره تأمین با تحلیل کلان داده
در بخش تولید، ظهور اینترنت اشیاء (IoT) و حسگرهای هوشمند، سیل عظیمی از دادهها را از خطوط تولید و تجهیزات جاری ساخته است. تحلیل کلان داده این دادهها را به بینشهای عملیاتی ارزشمند تبدیل میکند. نگهداری و تعمیرات پیشبینانه (Predictive Maintenance) یک نمونه کلاسیک است؛ به جای تعمیرات دورهای یا پس از خرابی، الگوریتمها با تحلیل دادههای عملکردی حسگرها، زمان احتمالی خرابی یک قطعه را پیشبینی کرده و امکان تعمیر پیشگیرانه را فراهم میسازند. این امر به شدت هزینههای ناشی از توقف خط تولید را کاهش میدهد. کاربردهای دیگر شامل کنترل کیفیت هوشمند با استفاده از تحلیل تصویر برای شناسایی عیوب، بهینهسازی لجستیک و زنجیره تأمین با ردیابی لحظهای محمولهها و پیشبینی زمان تحویل، و مدیریت بهینه موجودی انبارها است.
پیادهسازی تحلیل کلان داده: چه ساختار سازمانی برای موفقیت لازم است؟
موفقیت در تحلیل کلان داده تنها به انتخاب ابزارها و فناوریهای مناسب محدود نمیشود؛ این یک تحول فرهنگی و سازمانی است. برای اینکه بتوانید از دادهها به عنوان یک دارایی استراتژیک بهرهبرداری کنید، باید ساختار سازمانی خود را متناسب با این هدف بازآرایی نمایید. سازمانهای پیشرو دریافتهاند که رویکردهای سنتی و دپارتمانهای جزیرهای (Siloed) مانع بزرگی بر سر راه استفاده مؤثر از دادهها هستند. انتخاب ساختار مناسب به بلوغ، اندازه و فرهنگ سازمان شما بستگی دارد، اما مدلهای رایج و موفقی وجود دارند که میتوان از آنها الهام گرفت.
یکی از محبوبترین و مؤثرترین مدلها، ایجاد یک «مرکز تعالی تحلیل (Analytics Center of Excellence – CoE)» است. این مرکز به عنوان یک واحد متمرکز عمل میکند که مسئولیت تدوین استراتژی داده، تعیین استانداردها، ارائه مشاوره به واحدهای دیگر، و اجرای پروژههای پیچیده تحلیل کلان داده را بر عهده دارد. CoE معمولاً متشکل از متخصصان برجستهای مانند دانشمندان داده، مهندسان داده و تحلیلگران کسبوکار است. مزیت این مدل، تجمیع تخصص، جلوگیری از دوبارهکاری و تضمین همسویی ابتکارات دادهمحور با اهداف کلان کسبوکار است.
مدل دیگر، ساختار غیرمتمرکز یا فدرال (Decentralized/Federal Model) است. در این رویکرد، تیمهای تحلیل داده در دل واحدهای کسبوکار مختلف (مانند بازاریابی، مالی، عملیات) قرار میگیرند. این مدل باعث میشود تحلیلگران به نیازهای کسبوکار نزدیکتر باشند و راهحلهای بسیار کاربردیتری ارائه دهند. با این حال، ریسک ایجاد ناهماهنگی و استانداردهای متفاوت در سراسر سازمان وجود دارد. یک رویکرد ترکیبی (Hybrid) که در آن یک CoE مرکزی مسئولیت راهبری و تعیین استانداردها را بر عهده دارد و تیمهای تحلیل داده کوچکتر در واحدهای مختلف به صورت غیرمتمرکز فعالیت میکنند، اغلب بهترین نتیجه را به همراه دارد. صرف نظر از مدل انتخابی، ایجاد یک نقش ارشد مانند «مدیر ارشد داده (Chief Data Officer – CDO)» که مسئولیت نهایی استراتژی داده و حاکمیت آن را بر عهده دارد، یک گام حیاتی برای نشان دادن تعهد رهبری سازمان به تحول دادهمحور است.
تیم های کلیدی در اکوسیستم تحلیل کلان داده
هیچ پروژه تحلیل کلان داده موفقی بدون یک تیم متخصص، چندرشتهای و هماهنگ به سرانجام نمیرسد. جمعآوری استعدادهای مناسب و تعریف دقیق نقشها و مسئولیتها، یکی از مهمترین عوامل موفقیت در این مسیر پرچالش است. یک تیم تحلیل کلان داده مؤثر، ترکیبی از مهارتهای فنی، تحلیلی و کسبوکار را در خود جای داده است. در حالی که عناوین شغلی ممکن است در سازمانهای مختلف متفاوت باشد، نقشهای کلیدی زیر تقریباً در تمام تیمهای موفق مشترک هستند.
در ادامه به معرفی این نقشهای حیاتی و مسئولیتهای هر یک میپردازیم. این تیم مانند یک ارکستر عمل میکند که هر نوازنده باید ساز خود را به خوبی بنوازد تا یک سمفونی هماهنگ از بینشهای ارزشمند خلق شود. فقدان هر یک از این نقشها میتواند کل فرآیند را با چالشهای جدی مواجه سازد و مانع از دستیابی به ارزش واقعی سرمایهگذاری در تحلیل کلان داده شود.
- دانشمند داده (Data Scientist):این فرد، مغز متفکر تحلیلی تیم است. دانشمندان داده با تسلط بر آمار، یادگیری ماشین و روشهای مدلسازی پیشرفته، فرضیهها را آزمایش میکنند، مدلهای پیشبینانه میسازند و الگوهای پیچیده را از دل دادهها استخراج مینمایند. آنها به سوالات عمیق کسبوکار پاسخ میدهند و به دنبال کشف فرصتهای جدید هستند.
- مهندس داده (Data Engineer):اگر دانشمند داده یک کاوشگر است، مهندس داده معمار و سازنده زیرساختهاست. این افراد مسئول طراحی، ساخت و نگهداری «خطوط لوله داده» (Data Pipelines) هستند که دادهها را از منابع مختلف جمعآوری، پاکسازی، تبدیل و در یک سیستم قابل استفاده (مانند یک «دریاچه داده» یا Data Lake) ذخیره میکنند. بدون مهندسان داده، دانشمندان داده هیچ داده تمیز و قابل اعتمادی برای تحلیل نخواهند داشت.
- تحلیلگر داده (Data Analyst):این نقش، پلی میان دادههای فنی و کاربران کسبوکار است. تحلیلگران داده بر روی دادههای آماده شده توسط مهندسان کار میکنند تا گزارشها، داشبوردها و بصریسازیهای معناداری ایجاد کنند. آنها به سوالات مشخص کسبوکار پاسخ میدهند و نتایج تحلیلها را به زبانی ساده و قابل فهم برای مدیران ترجمه میکنند.
- تحلیلگر کسبوکار (Business Analyst):این فرد به طور عمیق با فرآیندها و نیازهای یک واحد کسبوکار خاص آشناست. وظیفه اصلی او، ترجمه چالشهای کسبوکار به سوالات قابل تحلیل برای تیم داده و همچنین اطمینان از اینکه بینشهای استخراج شده به اقدامات عملی در کسبوکار منجر میشوند، است.
- معمار داده (Data Architect):این نقش بر طراحی کلان اکوسیستم داده سازمان تمرکز دارد. معمار داده تصمیمات استراتژیک در مورد نحوه ذخیرهسازی، مدیریت و یکپارچهسازی دادهها را اتخاذ میکند و چشمانداز بلندمدت زیرساخت داده سازمان را ترسیم مینماید.

بهترین شیوه های پیاده سازی تحلیل کلان داده
سفر به سوی بلوغ در تحلیل کلان داده یک ماراتن است، نه یک دوی سرعت. سازمانهایی که در این مسیر موفق میشوند، مجموعهای از اصول و شیوههای برتر را دنبال میکنند که به آنها کمک میکند از دامهای رایج اجتناب کرده و بازگشت سرمایه (ROI) ملموسی از ابتکارات خود به دست آورند. این راهبردها صرفاً فنی نیستند، بلکه ترکیبی از استراتژی، فرهنگ و اجرا را در بر میگیرند. اتخاذ این شیوهها میتواند تفاوت میان یک پروژه پرهزینه و شکستخورده با یک قابلیت تحولآفرین و مزیتساز را رقم بزند.
در ادامه، به مجموعهای از این راهبردهای طلایی میپردازیم که بر اساس تجربیات سازمانهای پیشرو و گزارشهای معتبر موسساتی مانند «گارتنر» و «هاروارد بیزینس ریویو» گردآوری شدهاند. این اصول به شما کمک میکنند تا یک بنیان محکم برای فرهنگ دادهمحور در سازمان خود ایجاد کنید و اطمینان حاصل نمایید که تلاشهای شما در حوزه تحلیل کلان داده به نتایج پایدار و معنادار منجر میشود.
- با یک مشکل کسبوکار مشخص شروع کنید (Start with a Business Problem):بزرگترین اشتباه، شروع یک پروژه تحلیل کلان داده با تمرکز بر فناوری است. همیشه از یک سوال یا چالش مهم کسبوکار شروع کنید. به جای اینکه بپرسید «با این همه داده چه کار میتوانیم بکنیم؟»، بپرسید «مهمترین مشکل کسبوکار ما چیست و چگونه دادهها میتوانند به حل آن کمک کنند؟». این رویکرد تضمین میکند که نتایج پروژه، ارزشی مستقیم و قابل اندازهگیری برای سازمان خواهند داشت.
- فرهنگ دادهمحور را ترویج دهید (Foster a Data-Driven Culture):ابزارها و متخصصان به تنهایی کافی نیستند. رهبری سازمان باید به طور فعال فرهنگی را ترویج دهد که در آن تصمیمگیری بر اساس شواهد و دادهها ارزش تلقی میشود، نه صرفاً بر اساس شهود و تجربه. این امر شامل آموزش کارکنان برای سواد داده (Data Literacy) و تشویق به کنجکاوی و پرسشگری مبتنی بر داده است.
- بر حاکمیت و کیفیت داده تمرکز کنید (Focus on Data Governance and Quality):این ضربالمثل قدیمی که «آشغال ورودی، آشغال خروجی» (Garbage In, Garbage Out) در دنیای تحلیل کلان داده بیش از هر زمان دیگری صادق است. ایجاد یک چارچوب «حاکمیت داده» (Data Governance) برای تعریف مالکیت دادهها، استانداردها و سیاستهای کیفیت، یک پیشنیاز حیاتی است. سرمایهگذاری در پاکسازی و آمادهسازی دادهها شاید جذاب نباشد، اما ضروری است.
- کوچک شروع کنید و تکرار کنید (Start Small and Iterate):به جای تلاش برای اجرای یک پروژه عظیم و چند ساله، با پروژههای آزمایشی (Pilot) کوچک و قابل مدیریت شروع کنید که بتوانند در مدت زمان کوتاهی به «موفقیتهای سریع» (Quick Wins) دست یابند. این رویکرد نه تنها به تیم شما اجازه یادگیری و بهبود میدهد، بلکه با نشان دادن ارزش اولیه، حمایت مدیران و ذینفعان را برای پروژههای بزرگتر جلب میکند.
- بر داستانسرایی با دادهها تمرکز کنید (Focus on Data Storytelling):یک تحلیل پیچیده تا زمانی که به زبانی قابل فهم برای تصمیمگیران ترجمه نشود، بیارزش است. تیم شما باید بتواند یافتههای خود را در قالب یک داستان جذاب و متقاعدکننده، با استفاده از بصریسازیهای مؤثر، ارائه دهد. هدف نهایی، ارائه بینش (Insight) است، نه فقط انبوهی از دادهها و نمودارها.
گامبهگام تا موفقیت: مراحل اجرای یک پروژه تحلیل کلان داده
اجرای یک پروژه تحلیل کلان داده موفق نیازمند یک رویکرد ساختاریافته و مرحلهبندی شده است. عبور شتابزده از هر یک از این مراحل میتواند منجر به اتلاف منابع، نتایج غیردقیق و در نهایت شکست پروژه شود. این فرآیند چرخهای، که اغلب از متدولوژیهایی مانند «CRISP-DM» (Cross-Industry Standard Process for Data Mining) الهام گرفته شده، یک نقشه راه روشن برای تبدیل دادههای خام به ارزش تجاری فراهم میکند. در ادامه، این مراحل کلیدی را با تمرکز بر کاربرد آنها در پروژههای تحلیل کلان داده تشریح میکنیم.
فاز اول: تعریف استراتژی و اهداف در تحلیل کلان داده
درک مسئله کسب و کار در پروژه تحلیل کلان داده
این مرحله، سنگ بنای کل پروژه است. در اینجا، تیم داده با همکاری نزدیک با ذینفعان کسبوکار، مسئلهای را که قرار است حل شود، به دقت تعریف میکند. اهداف باید مشخص، قابل اندازهگیری، قابل دستیابی، مرتبط و زمانبندی شده (SMART) باشند. برای مثال، به جای هدف کلی «افزایش فروش»، یک هدف مشخص میتواند «کاهش نرخ ریزش مشتریان (Churn Rate) به میزان ۱۵٪ در شش ماه آینده از طریق شناسایی مشتریان در معرض خطر» باشد.
فاز دوم: زیرساخت و فناوری برای تحلیل کلان داده
انتخاب ابزارهای مناسب برای پروژه تحلیل کلان داده
پس از مشخص شدن اهداف، باید زیرساخت فنی مورد نیاز برای پشتیبانی از پروژه تحلیل کلان داده فراهم شود. این شامل انتخاب پلتفرمهای ذخیرهسازی (مانند دریاچه داده مبتنی بر Hadoop HDFS یا Amazon S3)، ابزارهای پردازش (مانند Apache Spark) و ابزارهای تحلیل و بصریسازی (مانند Tableau یا Power BI) است. این تصمیمات باید بر اساس حجم، سرعت و تنوع دادههای پروژه و همچنین مهارتهای موجود در تیم اتخاذ شوند.
فاز سوم: جمع آوری و مدیریت داده در پروژه های تحلیل کلان داده
فرآیند آماده سازی داده برای تحلیل کلان داده
این مرحله که اغلب زمانبرترین بخش پروژه است، شامل شناسایی منابع داده مورد نیاز، جمعآوری دادهها و سپس آمادهسازی آنها برای تحلیل است. فرآیند آمادهسازی شامل پاکسازی دادهها (رسیدگی به مقادیر گمشده و دادههای پرت)، یکپارچهسازی دادهها از منابع مختلف و تبدیل آنها به فرمتی مناسب برای مدلسازی است. کیفیت این مرحله تأثیر مستقیمی بر دقت نتایج نهایی تحلیل کلان داده دارد.
فاز چهارم: مدل سازی و تحلیل در فرآیند تحلیل کلان داده
بهکارگیری الگوریتمها در تحلیل کلان داده
در قلب هر پروژه تحلیل کلان داده، مرحله مدلسازی قرار دارد. در اینجا، دانشمندان داده با استفاده از تکنیکهای آماری و الگوریتمهای یادگیری ماشین، مدلهایی را برای کشف الگوها یا پیشبینی نتایج میسازند. انتخاب الگوریتم مناسب (مانند رگرسیون، طبقهبندی، خوشهبندی) بستگی به هدف مسئله دارد. مدلهای مختلفی ساخته و ارزیابی میشوند تا بهترین مدل با بالاترین دقت انتخاب شود.
فاز پنجم: استقرار، نظارت و بهینه سازی نتایج تحلیل کلان داده
عملیاتی کردن بینش های حاصل از تحلیل کلان داده
یک مدل تحلیلی تا زمانی که در فرآیندهای کسبوکار ادغام نشود، ارزشی ایجاد نمیکند. در این مرحله، مدل نهایی به صورت عملیاتی (Deployment) پیادهسازی میشود. برای مثال، مدل پیشبینی ریزش مشتری به سیستم CRM متصل میشود تا به صورت خودکار به تیم فروش هشدار دهد. پس از استقرار، عملکرد مدل باید به طور مداوم نظارت (Monitoring) شود و در صورت نیاز، با دادههای جدید بازآموزی و بهینهسازی گردد تا دقت آن در طول زمان حفظ شود. این چرخه تضمین میکند که نتایج تحلیل کلان داده همواره بهروز و مرتبط باقی بمانند.

رایجترین چالش ها در مسیر تحلیل کلان داده
اگرچه پتانسیل تحلیل کلان داده برای ایجاد تحول در کسبوکارها بسیار زیاد است، اما مسیر دستیابی به این پتانسیل هموار نیست. بسیاری از سازمانها در میانه راه با چالشهای فنی، سازمانی و فرهنگی مواجه میشوند که میتواند پیشرفت آنها را کند یا حتی متوقف کند. شناخت این موانع و برنامهریزی برای مقابله با آنها، یک گام اساسی برای افزایش شانس موفقیت است. مدیران باید دیدگاهی واقعبینانه نسبت به این چالشها داشته باشند و منابع لازم را برای غلبه بر آنها تخصیص دهند.
در ادامه، به بررسی برخی از رایجترین و مهمترین چالشهایی که سازمانها در سفر تحلیل کلان داده خود با آن روبرو میشوند، میپردازیم. آگاهی از این «سنگهای پیش پا» به شما کمک میکند تا استراتژی خود را با پیشبینی و آمادگی بیشتری تدوین کنید و از تکرار اشتباهات دیگران بپرهیزید.
- کیفیت و یکپارچگی دادهها (Data Quality and Integration):شاید بزرگترین چالش فنی، کیفیت پایین دادهها باشد. دادهها اغلب ناقص، ناسازگار و پراکنده در سیستمهای مختلف (سیلوهای داده) هستند. فرآیند پاکسازی، استانداردسازی و یکپارچهسازی این دادهها بسیار پیچیده و زمانبر است، اما نادیده گرفتن آن منجر به تحلیلهای نادرست و تصمیمات اشتباه میشود.
- کمبود استعداد و مهارتهای تخصصی (Talent and Skills Shortage):تقاضا برای متخصصان تحلیل کلان داده مانند دانشمندان و مهندسان داده بسیار بیشتر از عرضه است. جذب و نگهداری این استعدادهای کمیاب، یک چالش بزرگ برای بسیاری از سازمانهاست. علاوه بر این، نیاز به افزایش «سواد داده» در میان تمام کارکنان و مدیران نیز یک ضرورت فرهنگی است.
- امنیت دادهها و حریم خصوصی (Data Security and Privacy):جمعآوری و تحلیل حجم عظیمی از دادهها، به ویژه دادههای مشتریان، مسئولیتهای سنگینی را در زمینه امنیت و حفظ حریم خصوصی به همراه دارد. سازمانها باید از مقرراتی مانند GDPR پیروی کنند و با سرمایهگذاری در راهکارهای امنیتی، از دادهها در برابر دسترسیهای غیرمجاز و حملات سایبری محافظت نمایند. یک رخنه امنیتی میتواند آسیب جبرانناپذیری به اعتبار برند وارد کند.
- مقاومت سازمانی و فرهنگی (Organizational and Cultural Resistance):تغییر به سمت یک فرهنگ دادهمحور اغلب با مقاومت روبرو میشود. مدیران و کارکنانی که به تصمیمگیری بر اساس شهود و تجربه عادت کردهاند، ممکن است در برابر رویکردهای جدید مقاومت کنند. غلبه بر این چالش نیازمند حمایت قاطع رهبری، ارتباطات شفاف و نشان دادن ارزش ملموس پروژههای تحلیل کلان داده است.
- هزینههای بالای زیرساخت و ابزارها (High Cost of Infrastructure and Tools):پیادهسازی یک اکوسیستم تحلیل کلان داده میتواند نیازمند سرمایهگذاری قابل توجهی در سختافزار، نرمافزار و پلتفرمهای تخصصی باشد. اگرچه پلتفرمهای ابری (Cloud) این هزینههای اولیه را کاهش دادهاند، اما هزینههای جاری همچنان میتواند قابل توجه باشد. توجیه این سرمایهگذاری از طریق یک «طرح توجیهی کسبوکار» (Business Case) قوی، ضروری است.
مزایا و فرصت های طلایی تحلیل کلان داده برای کسب و کار شما
با وجود چالشهای موجود، دلایل قانعکنندهای وجود دارد که چرا سازمانهای پیشرو در سراسر جهان سرمایهگذاری سنگینی در تحلیل کلان داده میکنند. مزایای حاصل از این سرمایهگذاری، فراتر از بهینهسازیهای جزئی بوده و میتواند به خلق مزیتهای رقابتی پایدار و بازآفرینی مدلهای کسبوکار منجر شود. درک این فرصتهای طلایی به مدیران کمک میکند تا حمایت لازم را برای پیشبرد ابتکارات دادهمحور جلب کرده و تلاشهای خود را بر روی حوزههایی متمرکز کنند که بیشترین ارزش را ایجاد مینمایند.
در این بخش، به تشریح مهمترین مزایایی که تحلیل کلان داده میتواند برای سازمان شما به ارمغان بیاورد، میپردازیم. این مزایا، که جنبههای مختلفی از عملیات، استراتژی و ارتباط با مشتری را پوشش میدهند، نشان میدهند که چرا تحلیل کلان داده یک سرمایهگذاری استراتژیک با بازدهی بالا محسوب میشود.
- تصمیمگیری دادهمحور و هوشمندانه (Data-Driven and Smarter Decision-Making):این بنیادیترین مزیت تحلیل کلان داده است. با دسترسی به بینشهای دقیق و بهموقع از دادهها، مدیران میتوانند تصمیمات خود را از حالت مبتنی بر حدس و گمان به حالت مبتنی بر شواهد تغییر دهند. این امر منجر به کاهش ریسک، افزایش دقت پیشبینیها و تخصیص بهینهتر منابع در سراسر سازمان میشود.
- بهبود تجربه مشتری و شخصیسازی (Enhanced Customer Experience and Personalization):تحلیل کلان داده به شما امکان میدهد تا یک نمای ۳۶۰ درجه از مشتریان خود به دست آورید. با درک عمیق رفتار، نیازها و ترجیحات آنها، میتوانید محصولات، خدمات و کمپینهای بازاریابی خود را به صورت کاملاً شخصیسازی شده ارائه دهید. این سطح از شخصیسازی منجر به افزایش رضایت، وفاداری و در نهایت، ارزش طول عمر مشتری (Customer Lifetime Value) میشود.
- افزایش بهرهوری عملیاتی و کاهش هزینهها (Increased Operational Efficiency and Cost Reduction):از طریق تحلیل دادههای عملیاتی، میتوان گلوگاهها، ناکارآمدیها و فرآیندهای زائد را شناسایی و حذف کرد. کاربردهایی مانند نگهداری و تعمیرات پیشبینانه در تولید، بهینهسازی زنجیره تأمین در لجستیک، و تخصیص هوشمند منابع در خدمات، همگی به کاهش هزینهها و افزایش بهرهوری منجر میشوند.
- ایجاد نوآوری و مدلهای کسبوکار جدید (Innovation and New Business Models):بینشهای حاصل از تحلیل کلان داده میتواند منبع الهام برای نوآوری در محصولات و خدمات جدید باشد. علاوه بر این، برخی شرکتها با «محصولسازی دادهها» (Data Monetization)، یعنی فروش بینشهای agregated و ناشناس به دیگر شرکتها، جریانهای درآمدی کاملاً جدیدی برای خود ایجاد کردهاند.
- مدیریت ریسک پیشگیرانه (Proactive Risk Management):تحلیل کلان داده به سازمانها کمک میکند تا ریسکهای مالی، عملیاتی و امنیتی را قبل از وقوع، شناسایی و مدیریت کنند. الگوریتمهای تشخیص تقلب، مدلهای پیشبینی ریسک اعتباری و تحلیلهای پیشبینانه برای شناسایی تهدیدات سایبری، همگی نمونههایی از کاربرد این فناوری در مدیریت ریسک به صورت پیشگیرانه هستند.
معایب و ریسک های بالقوه تحلیل کلان داده
همانند هر فناوری قدرتمند دیگری، تحلیل کلان داده نیز دارای جنبههای تاریک و ریسکهایی است که باید با دقت مدیریت شوند. نگاهی یکجانبه و خوشبینانه به این حوزه میتواند سازمان را با مشکلات جدی اخلاقی، قانونی و استراتژیک مواجه کند. مدیران مسئولیتپذیر باید علاوه بر فرصتها، به معایب و خطرات بالقوه نیز توجه داشته باشند و سازوکارهای کنترلی لازم را برای کاهش این ریسکها پیادهسازی کنند. غفلت از این نکات احتیاطی میتواند به اعتبار برند، اعتماد مشتریان و حتی پایداری کسبوکار آسیب بزند.
ریسک سوگیری الگوریتمی در تحلیل کلان داده
یکی از بزرگترین خطرات در استفاده از مدلهای یادگیری ماشین، «سوگیری الگوریتمی» (Algorithmic Bias) است. اگر دادههایی که برای آموزش یک مدل استفاده میشوند، منعکسکننده سوگیریهای موجود در جامعه باشند (مثلاً در استخدام یا اعطای وام)، مدل نیز همان سوگیریها را یاد گرفته و در تصمیمگیریهای خودکار خود بازتولید و حتی تقویت خواهد کرد. این امر میتواند منجر به تبعیض ناخواسته و پیامدهای قانونی و اعتباری جدی برای سازمان شود. مقابله با این ریسک نیازمند نظارت دقیق بر دادههای ورودی و خروجی مدلها و استفاده از تکنیکهای «هوش مصنوعی منصفانه» (Fair AI) است.
چالش های حریم خصوصی و اخلاق داده در تحلیل کلان داده
مرز میان شخصیسازی مفید و تجاوز به حریم خصوصی بسیار باریک است. جمعآوری و تحلیل حجم عظیمی از دادههای شخصی، نگرانیهای جدی در مورد نحوه استفاده، ذخیرهسازی و به اشتراکگذاری این اطلاعات ایجاد میکند. سازمانها باید سیاستهای شفافی در زمینه «اخلاق داده» (Data Ethics) داشته باشند و فراتر از الزامات قانونی، به مسئولیت خود در قبال حفاظت از حریم خصوصی افراد عمل کنند. استفاده غیرمسئولانه از دادهها میتواند به سرعت اعتماد مشتریان را که به سختی به دست آمده است، از بین ببرد.
خطر تفسیر نادرست نتایج تحلیل کلان داده
دادهها به خودی خود حقیقت را بیان نمیکنند؛ آنها باید تفسیر شوند. همبستگی (Correlation) به معنای علیت (Causation) نیست و یک تحلیلگر بیتجربه ممکن است از دادهها نتایج نادرستی استخراج کند. اتخاذ تصمیمات استراتژیک بزرگ بر اساس یک تفسیر اشتباه از نتایج تحلیل کلان داده میتواند فاجعهبار باشد. به همین دلیل، پرورش «سواد داده» و تفکر انتقادی در سراسر سازمان و اطمینان از اینکه تحلیلها توسط افراد متخصص و با درک عمیق از زمینه کسبوکار انجام میشود، حیاتی است.
دانلود ابزارهای مدیریت کسب و کار

ابزارها و پلتفرم های قدرتمند در تحلیل کلان داده
اکوسیستم فناوری تحلیل کلان داده بسیار گسترده، پویا و در حال تکامل است. انتخاب مجموعه ابزارهای مناسب (Technology Stack) یکی از تصمیمات کلیدی در هر پروژه تحلیل کلان داده است و میتواند تأثیر قابل توجهی بر کارایی، مقیاسپذیری و هزینه آن داشته باشد. برای مدیران، درک دستهبندیهای اصلی این ابزارها و شناخت بازیگران کلیدی در هر حوزه، برای اتخاذ تصمیمات آگاهانه ضروری است. در این بخش، به معرفی مهمترین فناوریهایی که ستون فقرات پروژههای مدرن تحلیل کلان داده را تشکیل میدهند، میپردازیم.
ابزارهای ذخیره سازی و پردازش در تحلیل کلان داده
نقش Apache Hadoop و Spark در تحلیل کلان داده
در قلب بسیاری از زیرساختهای تحلیل کلان داده، دو پروژه متنباز بنیادین قرار دارند: «Apache Hadoop» و «Apache Spark». Hadoop با سیستم فایل توزیعشده خود (HDFS)، راهکاری مقیاسپذیر برای ذخیرهسازی حجم عظیمی از دادهها بر روی خوشهای از سرورهای معمولی فراهم میکند. Spark نیز یک موتور پردازش توزیعشده و بسیار سریع است که به دلیل پردازش در حافظه (In-memory processing)، عملکردی به مراتب بهتر از مدل «MapReduce» سنتی Hadoop دارد و به استاندارد دوفاکتو برای پردازش دادههای حجیم تبدیل شده است.
پایگاه های داده NoSQL در اکوسیستم تحلیل کلان داده
چرا NoSQL برای تحلیل کلان داده اهمیت دارد؟
پایگاههای داده رابطهای سنتی برای مدیریت تنوع و مقیاس دادههای حجیم مدرن طراحی نشدهاند. اینجا است که پایگاههای داده «NoSQL» (Not Only SQL) وارد عمل میشوند. این پایگاههای داده در انواع مختلفی مانند «سند-محور» (Document-oriented) مانند MongoDB، «کلید-مقدار» (Key-value) مانند Redis، و «ستون-خانواده» (Column-family) مانند Cassandra عرضه میشوند و انعطافپذیری و مقیاسپذیری افقی فوقالعادهای را برای مدیریت دادههای بدون ساختار و نیمهساختاریافته فراهم میکنند.
پلتفرمهای ابری برای تحلیل کلان داده
مزایای استفاده از Cloud در تحلیل کلان داده
ارائهدهندگان خدمات ابری بزرگ مانند «Amazon Web Services (AWS)»، «Microsoft Azure» و «Google Cloud Platform (GCP)» انقلابی در دسترسی به تحلیل کلان داده ایجاد کردهاند. این پلتفرمها مجموعهای کامل از خدمات مدیریتشده برای ذخیرهسازی (مانند Amazon S3, Azure Blob Storage)، پردازش (مانند Amazon EMR, Azure HDInsight) و تحلیل دادهها را ارائه میدهند. استفاده از ابر، نیاز به سرمایهگذاری اولیه سنگین در سختافزار را از بین برده و به سازمانها اجازه میدهد تا بر اساس نیاز خود، منابع را به صورت پویا و مقرونبهصرفه تأمین کنند.
ابزارهای بصریسازی و هوش تجاری در تحلیل کلان داده
اهمیت بصریسازی در فرآیند تحلیل کلان داده
آخرین حلقه در زنجیره تحلیل کلان داده، تبدیل بینشهای پیچیده به گزارشها و داشبوردهای قابل فهم است. ابزارهای مدرن هوش تجاری و بصریسازی داده مانند «Tableau»، «Microsoft Power BI» و «Looker» به کاربران اجازه میدهند تا به راحتی به منابع داده بزرگ متصل شده و با استفاده از رابطهای کاربری کشیدن و رها کردن (Drag-and-drop)، نمودارها و داشبوردهای تعاملی قدرتمندی بسازند. این ابزارها نقش حیاتی در دموکراتیزه کردن داده و توانمندسازی کاربران کسبوکار برای کشف بینشهای خود دارند.

افق های آینده: ترندهای نوظهور و جهت گیریهای آینده تحلیل کلان داده
حوزه تحلیل کلان داده به هیچ وجه ایستا نیست و با سرعتی سرسامآور در حال تحول است. برای مدیران استراتژیک، صرفاً درک وضعیت فعلی کافی نیست؛ بلکه باید نگاهی به آینده داشته باشند و خود را برای روندهای نوظهوری که چشمانداز این حوزه را در سالهای آینده شکل خواهند داد، آماده کنند. آگاهی از این جهتگیریها به سازمان شما کمک میکند تا از رقبا پیشی گرفته و از فرصتهای جدید در مراحل اولیه بهرهبرداری نمایید. در ادامه، به برخی از مهمترین ترندهایی که آینده تحلیل کلان داده را رقم میزنند، اشاره میکنیم.
تحلیل افزوده (Augmented Analytics) و آینده تحلیل کلان داده
چگونه هوش مصنوعی، خودِ فرآیند تحلیل کلان داده را متحول میکند؟
«تحلیل افزوده» که توسط «گارتنر» به عنوان یکی از مهمترین روندهای آینده معرفی شده، به استفاده از هوش مصنوعی و یادگیری ماشین برای خودکارسازی فرآیند تحلیل داده اشاره دارد. در این رویکرد، پلتفرمهای تحلیلی به صورت هوشمند دادهها را آمادهسازی میکنند، الگوهای مهم را به طور خودکار کشف مینمایند و بینشها را به زبان طبیعی برای کاربران توضیح میدهند. این روند، قدرت تحلیل کلان داده را از انحصار دانشمندان داده خارج کرده و در دسترس طیف وسیعتری از کاربران کسبوکار قرار میدهد.
تحلیل لبه (Edge Analytics) به عنوان یک پارادایم جدید در تحلیل کلان داده
پردازش داده در مبدأ و نقش آن در آینده تحلیل کلان داده
با انفجار دستگاههای اینترنت اشیاء (IoT)، انتقال تمام دادههای تولید شده به یک مرکز داده متمرکز یا ابر برای تحلیل، دیگر کارآمد و اقتصادی نیست. «تحلیل لبه» یک پارادایم جدید است که در آن، تحلیل دادهها به جای مرکز، بر روی خود دستگاهها یا در نزدیکی آنها (در لبه شبکه) انجام میشود. این رویکرد تأخیر را به شدت کاهش داده و امکان تصمیمگیری در لحظه را فراهم میکند، که برای کاربردهایی مانند خودروهای خودران یا نظارت صنعتی هوشمند حیاتی است.
بافت داده (Data Fabric) و یکپارچهسازی هوشمند در تحلیل کلان داده
راهکار معماری برای چالش پراکندگی داده در تحلیل کلان داده
«بافت داده» یک معماری نوظهور است که به دنبال حل مشکل پیچیدگی و پراکندگی دادهها در سازمانهای بزرگ است. به جای تلاش برای انتقال تمام دادهها به یک مکان واحد (مانند دریاچه داده)، بافت داده یک لایه مجازی و هوشمند ایجاد میکند که دسترسی یکپارچه به دادهها را بدون توجه به مکان فیزیکی آنها فراهم میسازد. این معماری با استفاده از هوش مصنوعی، فرآیندهایی مانند کشف داده، یکپارچهسازی و حاکمیت را خودکار کرده و مدیریت اکوسیستمهای داده پیچیده را سادهتر میکند.
چگونه هوش مصنوعی، قدرت تحلیل کلان داده را چندبرابر میکند؟
رابطه میان تحلیل کلان داده و هوش مصنوعی (AI)، به ویژه زیرشاخهی قدرتمند آن یعنی یادگیری ماشین (Machine Learning)، یک رابطه همافزایانه و تفکیکناپذیر است. این دو حوزه مانند دو بال یک پرنده عمل میکنند که با هم، سازمان را به ارتفاعات جدیدی از هوشمندی و کارایی میرسانند. درک این همگرایی برای هر مدیری که به دنبال استفاده از پتانسیل کامل دادههای خود است، حیاتی است. تحلیل کلان داده سوخت را فراهم میکند و هوش مصنوعی موتوری است که این سوخت را به حرکت، سرعت و جهت تبدیل میکند.
دادههای حجیم به عنوان ماده خام و خوراک اصلی برای الگوریتمهای هوش مصنوعی عمل میکنند. الگوریتمهای یادگیری ماشین برای یادگیری الگوها و انجام پیشبینیهای دقیق، به حجم عظیمی از دادههای متنوع و باکیفیت نیاز دارند. هرچه دادههای بیشتری در اختیار این الگوریتمها قرار گیرد، آنها هوشمندتر و دقیقتر میشوند. بدون وجود زیرساختها و قابلیتهای تحلیل کلان داده برای جمعآوری، ذخیره و پردازش این حجم از داده، بسیاری از پیشرفتهای شگفتانگیز اخیر در حوزه هوش مصنوعی، از تشخیص تصویر گرفته تا پردازش زبان طبیعی، امکانپذیر نبود.
از سوی دیگر، هوش مصنوعی به فرآیند تحلیل کلان داده معنا و قدرت میبخشد. در حالی که تحلیلهای سنتی ممکن است به کشف الگوهای ساده محدود شوند، الگوریتمهای یادگیری ماشین میتوانند روابط بسیار پیچیده و غیرخطی را در میان هزاران متغیر کشف کنند؛ الگوهایی که برای یک تحلیلگر انسانی تقریباً غیرممکن است که به تنهایی پیدا کند. این توانایی، تحلیل کلان داده را از سطح توصیفی و تشخیصی (آنچه اتفاق افتاده) به سطح پیشبینانه (آنچه اتفاق خواهد افتاد) و در نهایت، تجویزی (چه کاری باید انجام دهیم) ارتقا میدهد. به عنوان مثال، یک سیستم BI سنتی ممکن است به شما بگوید کدام مشتریان شرکت را ترک کردهاند، اما یک مدل یادگیری ماشین که با دادههای حجیم آموزش دیده، میتواند پیشبینی کند کدام مشتریان به احتمال زیاد در آینده شرکت را ترک خواهند کرد و بهترین اقدام برای حفظ آنها چیست. این همگرایی، عصر جدیدی از تصمیمگیری خودکار و هوشمند را آغاز کرده است.
چکلیست نهایی: آیا سازمان شما برای بهرهبرداری از تحلیل کلان داده آماده است؟
قبل از شروع یک سرمایهگذاری بزرگ در حوزه تحلیل کلان داده، بسیار مهم است که یک ارزیابی صادقانه از میزان آمادگی سازمان خود داشته باشید. شروع این سفر بدون آمادگی لازم، مانند ساختن یک آسمانخراش بر روی یک پی ضعیف است. این چکلیست به شما کمک میکند تا نقاط قوت و ضعف سازمان خود را در ابعاد مختلف استراتژیک، فرهنگی و فنی ارزیابی کنید و حوزههایی را که نیازمند توجه بیشتری هستند، شناسایی نمایید. پاسخ صادقانه به این سوالات، اولین گام در تدوین یک نقشه راه واقعبینانه و موفق برای تحول دادهمحور است.
- وضوح استراتژیک: آیا یک مشکل کسبوکار واضح و تعریفشده برای حل کردن با تحلیل کلان داده دارید؟آیا اهداف پروژه شما به طور مستقیم با اهداف استراتژیک کلان سازمان گره خورده است؟ آیا میتوانید موفقیت را به صورت کمی و با معیارهای مشخص (KPIs) اندازهگیری کنید؟
- حمایت رهبری: آیا مدیران ارشد سازمان، حامی و پشتیبان اصلی این ابتکار هستند؟آیا رهبری سازمان، اهمیت استراتژیک داده را درک کرده و آماده تخصیص منابع لازم (مالی و انسانی) و همچنین پذیرش تغییرات فرهنگی ناشی از آن است؟
- دسترسی و کیفیت دادهها: آیا به دادههای مورد نیاز برای تحلیل دسترسی دارید؟آیا از کیفیت، کامل بودن و صحت دادههای خود درک درستی دارید؟ آیا موانع سازمانی (سیلوهای داده) برای دسترسی به دادههای واحدهای مختلف وجود دارد؟
- استعداد و مهارتها: آیا تیم شما مهارتهای لازم برای اجرای پروژه تحلیل کلان داده را دارد؟آیا به متخصصانی مانند مهندسان داده، دانشمندان داده و تحلیلگران دسترسی دارید؟ آیا برنامهای برای آموزش و ارتقای «سواد داده» در سراسر سازمان دارید؟
- فرهنگ سازمانی: آیا فرهنگ سازمان شما پذیرای تصمیمگیری مبتنی بر داده است؟آیا کارکنان و مدیران تشویق میشوند که فرضیههای خود را با دادهها به چالش بکشند؟ آیا سازمان شما از شکستهای هوشمندانه به عنوان فرصتی برای یادگیری استقبال میکند؟
- زیرساخت فنی: آیا زیرساخت فناوری اطلاعات شما برای مدیریت و پردازش حجم عظیمی از دادهها آماده است؟آیا معماری داده فعلی شما مقیاسپذیر و انعطافپذیر است؟ آیا استراتژی مشخصی برای استفاده از فناوریهای ابری یا داخلی (On-premise) دارید؟
نقش ما به عنوان مشاور: چگونه میتوانیم شما را در مسیر تحلیل کلان داده همراهی کنیم؟
سفر به سوی بلوغ در تحلیل کلان داده، مسیری پیچیده و پر از چالشهای استراتژیک، فنی و فرهنگی است. همانطور که در این مقاله بررسی کردیم، موفقیت در این حوزه نیازمند چیزی فراتر از خرید نرمافزار و استخدام چند متخصص است؛ این یک تحول بنیادین در نحوه تفکر، تصمیمگیری و عملکرد سازمان شماست. در مشاوره مدیریت رخ، ما درک میکنیم که هر سازمان منحصر به فرد است و یک راهحل یکسان برای همه وجود ندارد. نقش ما به عنوان مشاوران شما، همراهی گامبهگام در این سفر تحولآفرین و کمک به شما برای عبور هوشمندانه از موانع و دستیابی به نتایج ملموس تجاری است.
ما میتوانیم به شما در تدوین استراتژی داده متناسب با اهداف کسبوکارتان کمک کنیم، یک نقشه راه واقعبینانه برای پیادهسازی طراحی نماییم، در انتخاب معماری و ابزارهای فنی مناسب شما را راهنمایی کنیم، و در ساختن یک تیم قدرتمند و ترویج فرهنگ دادهمحور در کنارتان باشیم. تخصص ما در تقاطع مدیریت استراتژیک و فناوری، به ما این امکان را میدهد که پلی میان دنیای کسبوکار و دنیای پیچیده تحلیل کلان داده ایجاد کنیم و اطمینان حاصل نماییم که سرمایهگذاری شما به بازدهی پایدار و مزیت رقابتی منجر خواهد شد. اگر آمادهاید تا قدرت واقعی دادههای خود را آزاد کنید، ما آمادهایم تا شما را در این مسیر هیجانانگیز همراهی کنیم.


ابزارها





























محمدمهدی صفایی میگه:
مظاهری میگه:
Mz میگه: